Prediction intervals #
In classical linear regression, a prediction comes with an assessment of confidence. Here is a short and mostly correct summary how this roughly works. Suppose that we are assuming a linear model for a data set of input-output pairs \(\mathcal{D} = \{(x_i, y_i)\}_i\), or more precisely, that
\[ y = mx+b + \epsilon \]
where \(m\) and \(b\) are constants and \(\epsilon\) is an error term whose average value is zero. It is possible to estimate \(m\) and \(b\) from data and use this model to make predictions. For input \(x_i\), our estimate for the corresponding output \(y_i\) would be \(\hat{y}_i = m x_i + b\). But it is highly unlikely that this so-called point estimate is exactly correct. It is much more reasonable to ask for a range of possible values.
In classical regression, one usually assumes that \(\epsilon\) is normally-distributed, the variance of distribution can be estimated from the data, and a prediction interval of the form
\[ \hat{y}_i \in [ mx_i+b -c ,mx_i+b +c ] \]
can be computed. The larger the constant \(c\), the larger our confidence that the true value \(y_i\) lies in this interval.
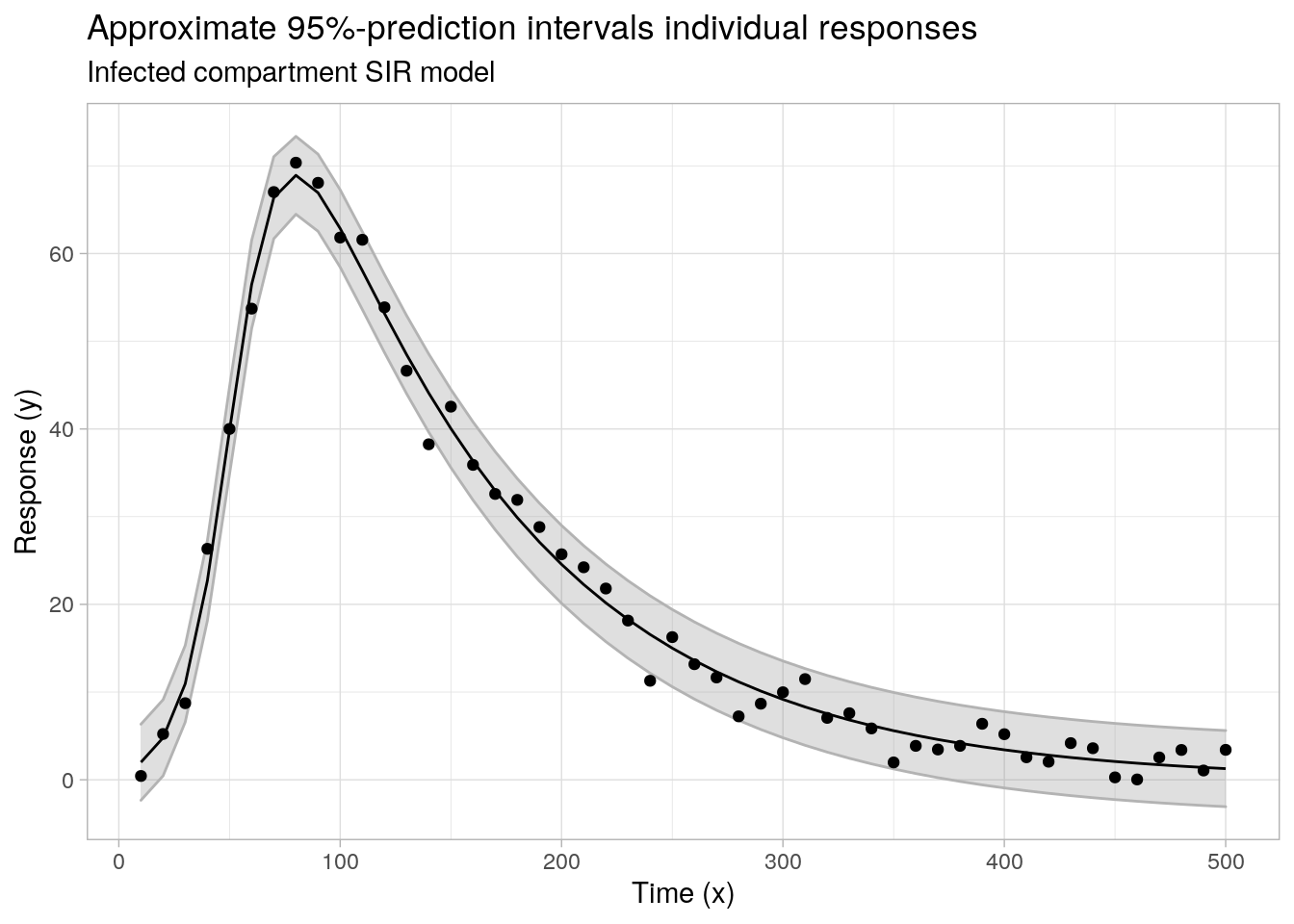
from Joris Chau
But linear regression assumes that a very simple model generates \(\mathcal{D}\) and any complexity is simply incorporated into the noise, or error, term. A more complex regression model, such as one coming from neural networks, can potentially incorporate some of this complexity and reduce the size of the error term. However, making predictions in the form of confidence intervals is not well-studied for such regression models. Hence this project.
A bootstrapping approach to prediction intervals #
The goal of this project is to empirically analyze a new approach to making predictions not as single values but as prediction intervals when using neural networks for regression. In this paper, the authors use the classical (by which I mean from the late 1970s) technique of bootstrapping. Here is an outline of a possible project:
-
Read an introduction to bootstrapping. Here is an introduction with Python code.
-
Generate synthetic data with a known error model and therefore a known model for prediction intervals. Train regressive neural networks, and use bootstrapping to estimate these prediction intervals. Are they the same, and does your answer depend on the neural network architecture and training procedure? Note: this is a natural experiment that the authors of the paper above did not do!
-
Repeat the above but this time with your favorite data set. You may replicate one done in the original paper, or choose one of your own.