The double descent phenomenon #
Background #
The recently-discovered double descent phenomenon is at the heart of recent advances in machine learning and artificial intelligence. When fitting a parameter-based model to data, the long-standing question has always been: how many parameters should one use? Historically, there have been three schools of thought. Suppose that our data set \(\mathcal{D} = \{ (\vec{x}_i, \vec{y}_i) \} \) consists on \(n\) points and \(p\) is the number of parameters in our model.
- In the under parametrized regime, \( p \ll n\). This is the setting for linear regression and describes a large portion of the methods of traditional statistics where \(p\) often equals two or three Even though you may have a large data set, the underlying assumption is that there is a simple model which generated it. John von Neumann, who liked simple and explainable models, summarized this philosophy in a short quip made to Freeman Dyson:
With four parameters I can fit an elephant, and with five I can make him wiggle his trunk.
-John von Neumann
-
At the interpolation threshold, \( p = n\). Simply put, when the number of unknown parameters is the same as the number of data points, at least in theory one should be able to find a model that exactly fits the data points. Think of this like having \(n\) equations with \(n\) unknowns. We have seen this in the setting of regression, where it is always possible to find a polynomial of degree \(n-1\) that fits \(\mathcal{D}\) as long as all the input variables are different. Models at the interpolation threshold are rarely good at generalizing and suffer from overfitting.
-
In the overparametrized regime, \( p \gg n\). Historically, this has been a mythical place off the edge of the map where all feared to tread: hic sunt leones. If models at the interpolation threshold are prone to overfitting, why would anyone try to build models that use even more parameters! However, in recent years, computer scientists who apparently missed the warnings in their mathematics classes have done just this, and it worked remarkably well. Many machine learning models rely on billions if not trillions of parameters far exceeding the size of the data sets used to train them.

Double descent in the overparametrized regime #
The goal of this project is to investigate the success of overparametrized models. It can be summarized in the following graph, where the generalization error, that is, error on a validation set, is plotted against the number of parameters used to build the model.
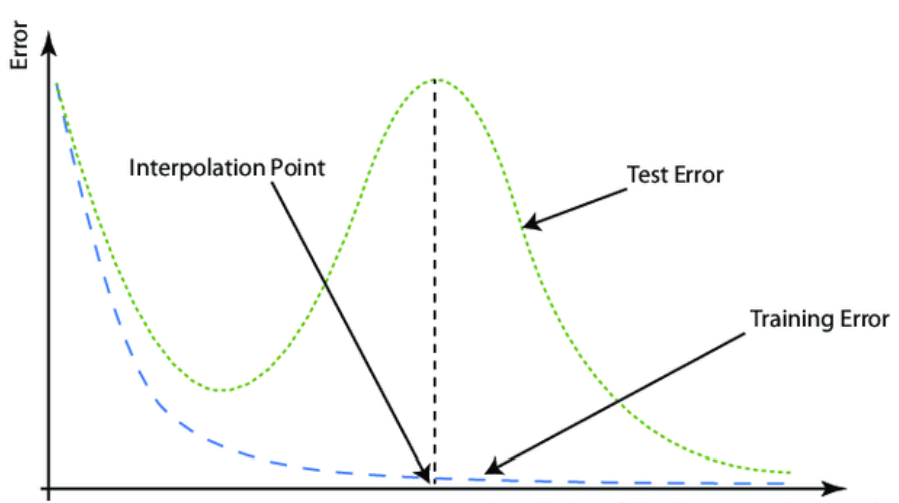
The project has two parts, one empirical and one theoretical. Feel free to choose which parts you consider or emphasize in this project.
Project outline #
-
Background reading: Start by reading the recent article Double Descent Demystified by Rylan Schaeffer et al. Don’t sweat the details, but try to get an overview of what the authors have done. Feel free to augment your reading with articles from the reading rack below, or any of the myriad of online articles that have been generated by ChatGPT about this.
-
Empirical work: Pick your favorite data set and a regression or classification model and attempt to recover the double descent phenomenon by training models with different numbers of parameters. Usually, phenomena like this are logarithmic, so work using powers of 2 rather than changing the number of parameters linearly. You probably will have to adjust how you learn the model: for instance, the learning rate used in gradient descent for one model size may not be a good one to use on another. Repeat with other data sets. Are there data sets or circumstances where this phenomenon does not occur?
-
Theoretical work: Is there theoretical work that supports double descent? Do a literature review, find a reference or two that provide a compelling justification, and make it your own as a part of your final paper. The jury is definitely still out on this matter, so you may stumble onto not only poorly-stated conjectures, but some of them may even contradict each other.
Reading rack #
Here are some articles related to double descent on my personal reading rack. Some are well and some are poorly written, so tread carefully. There is a skill to reading a research article to extract exactly the piece of information that you need from it, so don’t be too frustrated at first. Don’t expect to understand everything; sometimes, the authors don’t either.